Um es vorweg zu sagen, ich beschäftige mich in diesem Artikel mit Influx zur Erzeugung von Diagrammen ausschließlich in Node-Red. Es gibt auch andere, leistungsfähigere Diagrammlösungen wie Grafana. Die dabei zu durchlaufende Lernkurve ist allerdings sehr steil und außerdem haben wir anschließend ein weiteres System an der Hand, so dass wir zwischen Diagrammen und Einstellungen immer hin- und herspringen müssen. Ich finde, Analysen und Befehle auf einer einzigen User-Interfaceschicht besser. Auch wenn Node-Red, was Diagramme angeht, nicht so viel kann, für den Hausgebrauch reicht es. Ein weiterer Vorteil von Node-Red ist, dass die Darstellung auf mobilen Endgeräten besser ist.
Nachteil ist, dass wir die in Influx seriell abgespeicherten Daten erst mit etwas Aufwand in JSON umwandeln müssen. Aber das ist ein lehrreicher Einmalaufwand – siehe weiter unten.
Wie schon im vorigen Kapitel geschrieben, konzentriere ich mich auf Influx Version 1.8 mit dem Command Line Interface.
Das Influx Command Line Interface (CLI) ist richtig Old School; Look and Feel erinnern an das selige dBase von vor 40 Jahren. Die Befehle sind auch sehr ähnlich, wer schon einmal SQL Abfragen gebaut hat, wird sich sehr schnell zu Hause fühlen. Alle anderen müssen sich jedoch keine Sorgen machen, ich erkäre das im Folgenden.
Erste Schritte
Influx CLI
Der Aufruf erfolgt im RaspbianTerminal ganz einfach mit influx . Falls das nicht klappt, bitte bei meinem Artikel Viessmann API und Node-Red – Teil 6a nachsehen. Da steht, wie man Influx installiert.
Wir legen als nächstes eine Datenbank namens apidata an: create database apidata. Der Name ist natürlich wahlfrei.
In einer einzelnen Datenbank können mehrere verschiedene Tabellen mit Messwerten stecken. z.B. Temperatur, Betriebsdauer, Verbrauch. Diese Tabellen heißen Buckets (Eimer), die dort hineingeschriebenen Messwerte nennt man Measurements (Messungen).
Fake Daten generieren mit Node-Red
Bauen wir uns erst einmal einen kleinen Datenzoo aus Fake-Werten: Dazu brauchen wir einen Inject-, Funktions– und einen Influx Out-Node. Eventuell sind die Influx Nodes noch nicht vorhanden. Dann müssen wir sie über die Node-Red Palettenverwaltung nachinstallieren.
Der Inject Node sollte so eingestellt werden, dass er alle paar Minuten ein Timestamp losschickt.

Der function node sieht so aus:
|
1 2 3 4 |
//Insert Query mit Zufallswerten für Temperatur var twert = Math.floor(Math.random() * 20); msg.payload = twert; return msg; |
Der Influx out Node wird wie folgt eingestellt:
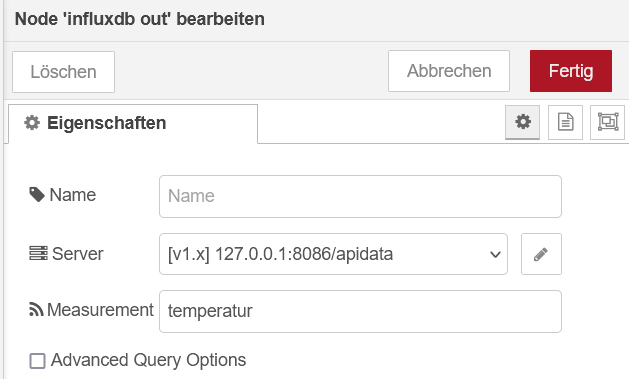
Node-Red nennt hier den (oder die?) Bucket "Measurement", was meines Erachtens etwas doppeldeutig ist.
Will man Temperaturen von mehreren Messstationen in demselben Bucket abspeichern, (z.B. für Nordseite oder Terrasse) dann brauchen wir noch ein so genanntes Tag (Etikett), das dem Wert in der Payload mitgegeben wird. Wird die Payload wie oben dargestellt so mir nichts dir nichts übergeben, bekommt der Wert die Überschrift "value", was bei komlexeren Datenstrukturen nicht gerade aussagekräftig ist. Deshalb sollten wir noch entsprechenden Überschriften für das Tag und den Wert mitliefern. Der Funktionsnode sieht dann so aus:
|
1 2 3 4 |
//Insert Query mit Zufallswerten var twert = Math.floor(Math.random() * 20); msg.payload = {ort: "Nordseite", gradc: twert}; return msg; |
Die Payload wird hiermit zu einem Objekt. Das Tag für den Ort ist hier "Nordseite" und die Temperaturwerte bekommen die Überschrift "gradc".
Arbeiten mit echten Daten
Im "echten Leben", also ohne Fake Daten wird der influx in Node direkt mit dem Datenoutput aus unserer API verkabelt.

Fragt man nun die Viessmann Daten alle 90 Sekunden ab, werden über den Tag 960 Werte weggespeichert. Viele davon sind gleich, da sich die Lufttemperatur nicht andauernd ändert sondern über Stunden gleich bleibt. Daher ist es besser, einen Filter einzubauen, damit unsere Datenbank sparsam befüllt wird:

Der Filter Node schickt empfangene Daten nur weiter, wenn sie sich gegenüber dem vorherigen Datum geändert haben. Sehr praktisch!
Daten mit Influx ansehen
Springen wir zurück zu unserer Tabelle mit den gefaketen Werten und lassen den Flow ein paar Minuten oder länger laufen – oder klicken mehrmals auf den Inject Node. Ansehen können wir uns die Rohdaten wieder im Influx CLI mit select * from temperatur
Das wird allerdings einen Fehler ERR: database name required produzieren. Wir müssen zuerst die zu verwendende Datenbank mit use apidata setzen – dann funktioniert's.
Das Ergebnis mit unseren Phantasiewerten sieht ungefähr so aus:
|
1 2 3 4 5 6 7 |
> select * from temperatur name: temperatur time gradc ort ---- ----- --- 1675529440180191561 11 Nordseite 1675529740177792060 16 Nordseite 1675530040178699621 19 Nordseite |
Die Spalte time enthält den Unix Timestamp auf Nanosekunden genau. Eigentlich ein Overkill, aber es ist halt so. Die Website Unix time stamp ist sehr hilfreich dabei, diese Daten hin oder her zu konvertieren.
Der 19-stellige Nanosekunden genaue Timestamp ist für Node Red etwas zuviel. Damit Node Red mit diesen Timestamps rechnen kann, müssen wir den Timestamp durch 1000 dividieren, d.h. auf Millisekunden kürzen. Das macht man am einfachsten mit der Number()Methode.
Will man die Daten der letzten 3 Stunden abfragen, lautet der Befehl:
select time, gradc from temperatur where time > (now() - 3h)
Influxdb 1.8 erlaubt folgende Literale für die Zeitdauer:
- microseconds: u or µ
- milliseconds: ms
- seconds: s
- minutes: m
- hours: h
- days: d
- weeks: w
Inflix 2.x kann da etwas mehr. Bei 1.8 fehlt z.B. 1mo für einen Monat.
Eine Dokumentation der Influx Abfragesprache findet ihr hier.
Darstellung mit Node-Red
Wie schon beschrieben, muss man die in Influx steckenden seriellen Daten erst in ein JSON Objekt konvertieren, bevor man sie in einem Node-Red Diagramm darstellen kann. Ich habe mich hier von folgender Website inspirieren lassen: https://funprojects.blog/2020/02/01/influxdb-with-node-red/
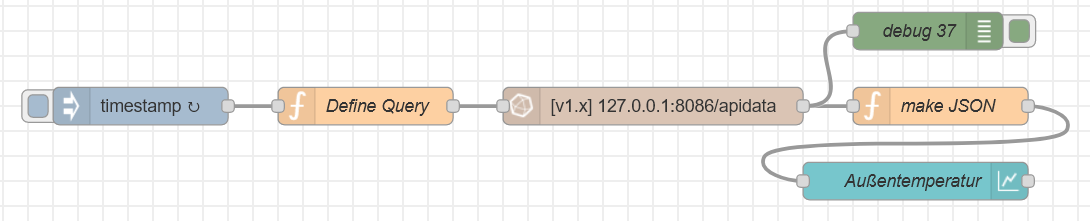
Der Node Define Query enthält die oben stehende Abfrage für Werte der letzten 3 Stunden wie folgt:
|
1 2 |
msg.query ='select time, gradc from temperatur where time > now() - 3h'; return msg; |
Der influxdb in Node enthält lediglich den Server und die Datenbank und liefert als Output ein Array der Art
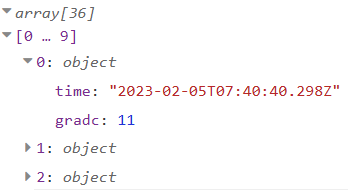
Man könnte die Query auch direkt in den Influxdb in Node schreiben, warum auch immer, ich finde es besser, die Query sauber getrennt in einem eigenen Knoten unterzubringen.
Liniendiagramm
Der Node make JSON ist etwas komplexer – Erklärung in den Kommentaren:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
var series = ["Temp. Nordseite"]; //Beschriftung der Linie bei Mouse Over var labels = ["Werte"]; // wichtig für Payload - Inhalt egal var data = "[["; // Anfang des generierten JSON Strings var thetime; // Variable für gerade gelesenen Zeitstempel for (var i = 0; i < msg.payload.length; i++) { //Schleife über die Anzahl der Payload Elemente thetime = Number(msg.payload[i].time); // Number() macht aus Nanosekunden Millisekunden, NR kann mit langen Timestamps nicht rechnen data += '{ "x":' + thetime + ', "y":' + msg.payload[i].gradc + '}'; //gelesenen Timestamp und Wert in JSON String schreiben if (i < (msg.payload.length - 1)) { // Check ob alles gelesen data += "," // wenn nein, trennendes Komma in JSON String einfügen } else { // sonst data += "]]" // JSON String abschließen } } var jsondata = JSON.parse(data); // Umwandeln JSON String in JSON Objekt msg.payload = [{ "series": series, "data": jsondata, "labels": labels }]; // Datensatz für NR Linechart return msg; |
Heraus kommt ein – in unserem Fall weitgehend sinnloses – Liniendiagramm:
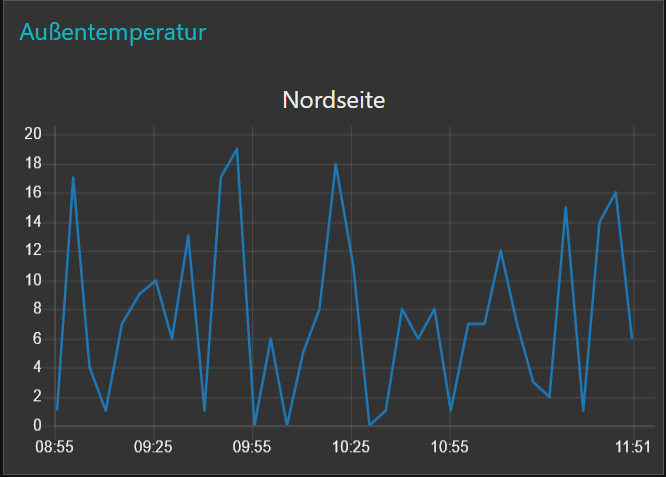
Das Schöne ist, wir können den oben dargestellten make JSON Node beliebig weiterverwenden. Anzupassen sind lediglich der Wert der "Series" Variablen sowie die Variable bei msg.payload[i].gradc .
Mehr Flexibilität
Vielleicht willst du die Zeitspanne, für welche die Daten ausgewertet werden etwas flexibler gestalten. Das geht recht einfach über den dropdown Node des Dashboards.

Das Dropdown kann z.B. wie folgt befüllt werden:
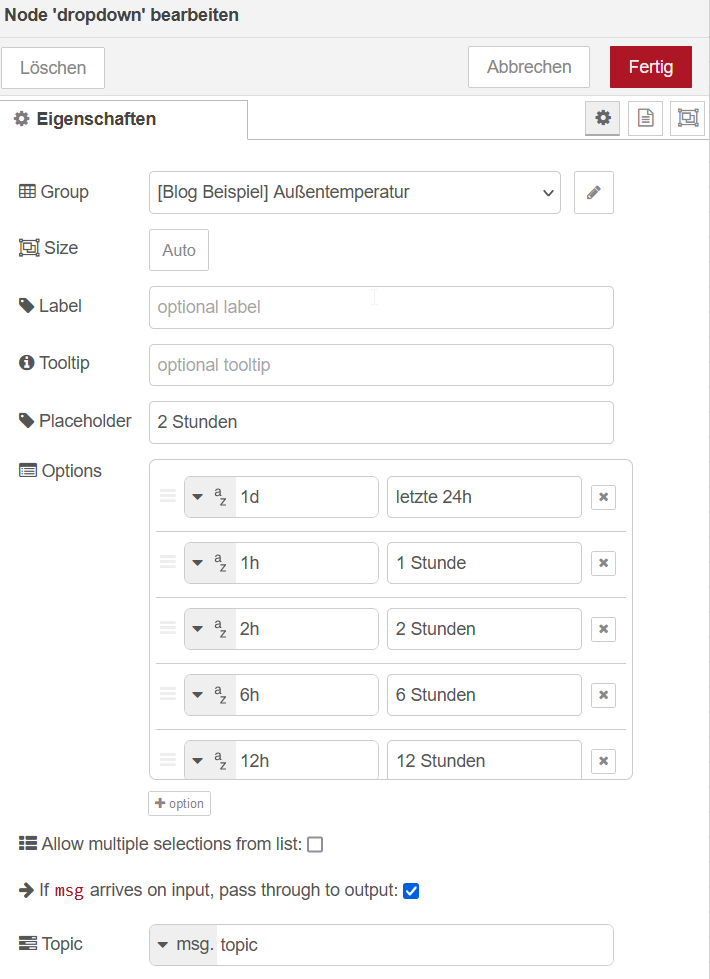
Der Query Node wird geringfügig modifiziert:
|
1 2 |
msg.query ='select time, gradc from temperatur where time > now() - ' + msg.payload; return msg; |
Breitere Linien und Schraffuren
Fügt man vor dem return msg; Kommando des make JSON Nodes noch folgende Befehle ein, kann man die Darstellung der Linie etwas aufhübschen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//+++++++++++++++++++++++++++++ msg.ui_control = { "options": { "elements": { "line": { "borderWidth": 5, "fill": true, "interpolate": "step", }, "point": { "radius": 0 } } } } //++++++++++++++++++++++++++++++ |
borderWidth stellt die Breite in Pixel ein, steht der fill Parameter auf true, wird der Bereich unterhalb der Linie transparent in Linienfarbe schraffiert.
Problem dabei ist, dass sich diese Methode auf sämtliche Linien des Line-Charts auswirkt, bei Multi Value Line-Charts also eher nicht zu empfehlen.
Balkendiagramme
Balkendiagramme sind auch möglich. Allerdings müssen wir hier etwas mehr Mühe in die Label Variablen stecken – beim Line Chart konnten wir die ja beliebig gestalten.
Verbrauch anzeigen
Den Tages-Verbauchswert in kW kannst du (neben anderen Verbrauchswerten) aus der API abgreifen:
|
1 2 |
var idx = featureArray.findIndex((element) => element.feature === 'heating.gas.consumption.total'); msg.payload = msg.payload.data[idx].properties.day.value[0]; |
Kurz vor 24 Uhr sollte dieser Wert dann in die InfluxDB geschrieben werden, damit wir eine tageweise Auswertung fahren können.
Lange Rede, kurzer Sinn, hier ist das JSON File zum importieren in Node-Red – der Make JSON Funktionsnode ist ausführlich kommentiert:
|
1 |
[{"id":"a238ea5bcd74a042","type":"ui_chart","z":"dff40f773b14f98a","name":"","group":"72a2229e7be23694","order":5,"width":"0","height":"0","label":"Liter GPL","chartType":"bar","legend":"false","xformat":"HH:mm:ss","interpolate":"linear","nodata":"waiting","dot":false,"ymin":"0","ymax":"","removeOlder":1,"removeOlderPoints":"","removeOlderUnit":"3600","cutout":0,"useOneColor":true,"useUTC":false,"colors":["#1f77b4","#aec7e8","#ff7f0e","#2ca02c","#98df8a","#d62728","#ff9896","#9467bd","#c5b0d5"],"outputs":1,"useDifferentColor":false,"className":"","x":1240,"y":760,"wires":[[]]},{"id":"e1327a4006ba5802","type":"function","z":"dff40f773b14f98a","name":"make JSON","func":"function round(value, decimals) { // Funktion zum Runden der Werte\n return Number(Math.round(value + 'e' + decimals) + 'e-' + decimals);\n}\n\nvar series = [\"ltr\"]; // Einheiten in Liter GPL - anpassen an die verwendete Einheit kWh o.ä.\nvar labels = \"[\"; // Beginn des JSON Strings für die Labels\nvar data = \"[[\"; // Beginn des JSON Strings für die Werte\nvar thetime; // speichert die aktuel gelesene Zeit\n\nfor (var i = 0; i < msg.payload.length; i++) { // Schleife über alle Werte\n thetime = Number(msg.payload[i].time); // Lesen der Zeit und konvertieren in ms\n data += round(msg.payload[i].value, 1); // Gerundetetn Wert an Datenarray anfügen\n var d = new Date(thetime); // Datum aus Timestring ziehen\n var day = d.getDate(); // Tag aus Datum ziehen \n var month = d.getMonth() + 1; // Monat aus Datum ziehen\n labels += '\"' + day + '/' + month + '\"'; // Tag/Monat in Labelarray schreiben \n if (i < (msg.payload.length - 1)) { // solange noch Werte da\n data += \",\" // Array mit Trennkomma versehen\n labels += ',' // dito Labelarray\n } else { // sonst \n data += \"]]\" // JSON Strings abschließen\n labels += \"]\"\n }\n}\n//msg.payload = labels; // hilfreich für Testzwecke\nvar jsondata = JSON.parse(data); // JSONObjekt aus String erzeugen\nvar jsonlabels = JSON.parse(labels); // dito für Labels\nmsg.payload = [{ \"series\": series, \"data\": jsondata, \"labels\": jsonlabels }]; // Übergabe an Barchart\nreturn msg;\n","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":990,"y":760,"wires":[["a238ea5bcd74a042","5cfaa4df526f8f4b"]]},{"id":"99b2d04c0b6ac58a","type":"influxdb in","z":"dff40f773b14f98a","influxdb":"3aa60ef18acf78e3","name":"","query":"","rawOutput":false,"precision":"","retentionPolicy":"","org":"organisation","x":740,"y":760,"wires":[["e1327a4006ba5802"]]},{"id":"229e7a9670314daa","type":"function","z":"dff40f773b14f98a","name":"Define Query","func":"msg.query ='select time, value from verbrauch where time > now() - ' + msg.payload;\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":510,"y":760,"wires":[["99b2d04c0b6ac58a","63458a37f6a9c260"]]},{"id":"5cfaa4df526f8f4b","type":"debug","z":"dff40f773b14f98a","name":"debug 39","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":1240,"y":800,"wires":[]},{"id":"7e146baebb72cb66","type":"inject","z":"dff40f773b14f98a","name":"","props":[{"p":"payload"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"00 03 * * *","once":true,"onceDelay":0.1,"topic":"","payload":"30d","payloadType":"str","x":150,"y":760,"wires":[["27f5113d48cbe20f"]]},{"id":"27f5113d48cbe20f","type":"ui_dropdown","z":"dff40f773b14f98a","name":"","label":"","tooltip":"","place":"30 Tage","group":"72a2229e7be23694","order":1,"width":6,"height":1,"passthru":true,"multiple":false,"options":[{"label":"gestern","value":"1d","type":"str"},{"label":"1 Woche","value":"1w","type":"str"},{"label":"30 Tage","value":"30d","type":"str"},{"label":"90 Tage","value":"90d","type":"str"},{"label":"1 Jahr","value":"365d","type":"str"}],"payload":"","topic":"topic","topicType":"msg","className":"","x":320,"y":760,"wires":[["229e7a9670314daa"]]},{"id":"72a2229e7be23694","type":"ui_group","name":"Verbrauch","tab":"713a8ca9566dabdd","order":7,"disp":true,"width":"6","collapse":false,"className":""},{"id":"3aa60ef18acf78e3","type":"influxdb","hostname":"127.0.0.1","port":"8086","protocol":"http","database":"apidata","name":"","usetls":false,"tls":"","influxdbVersion":"1.x","url":"http://localhost:8086","rejectUnauthorized":true},{"id":"713a8ca9566dabdd","type":"ui_tab","name":"Blog Beispiel","icon":"dashboard","disabled":false,"hidden":false}] |
Hat alles geklappt bekommen wir ein Balkendiagramm dieser Art:
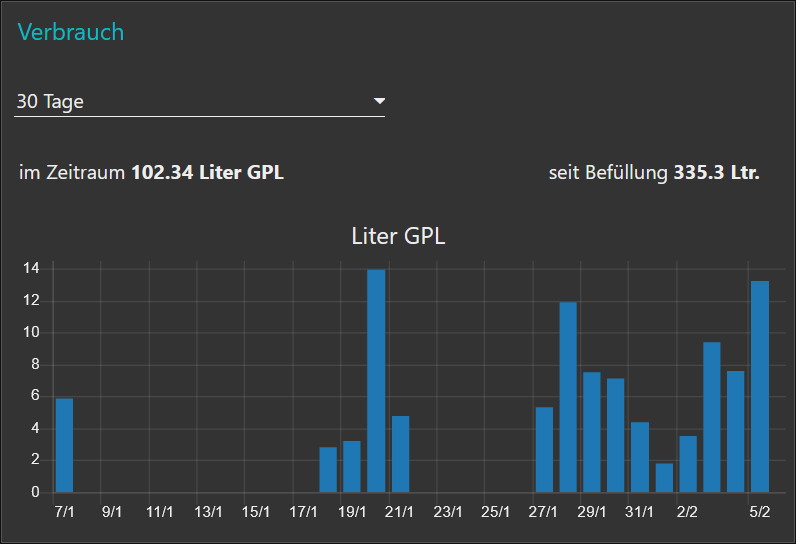
Das Datum "seit Befüllung" wird extra berechnet und ist nicht Bestandteil des obigen JSON Codes.
In meinem Node-Red Setup generiere ich den momentanen und täglichen Gasverbrauch aus
Modulation in % * Zeitdauer * Kesselleistung . Die Modulation wird bei mir alle 90 Sekunden abgefragt: habe ich über den Tag z.B. eine durchschnittliche Modulation von 30%, dann muss ich das nur mit den 19kWh des Kessels multiplizieren und erhalte dann einen Tagesenergieverbrauch von 0,3 * 19kWh * 24 = 136,8 kWh. Das kann ich dann je nach dem spezifischen Energiegehalt des Brennstoffs umrechnen in
z.B. Erdgas 136[kW] / 10,36 [kW/m³] = 13m³ oder
Propangas 136[kW] / 7,3 [kW/Liter] = 18,6 Liter GPL
Klingt zuerst einmal etwas umständlich. Beim Momentanverbrauch ist diese Methode jedoch genauer – Viessmann aktualisiert den kWh Wert nämlich nur jede Stunde.
Aggregierte Werte
Wie jede gute Datenbank bietet Influx auch die Möglichkeit, Werte nach Tagen, Wochen etc. zu aggregieren. Leider kommt uns jetzt der geringere Funktionsumfang der Version 1.8 in die Quere. Monatsweises aggregieren geht in der Datenbank nur mit Klimmzügen, da das Zeitspannenliteral "mo" für Monat erst in 2.x eingeführt wurde.
Wir könnten uns zwar mit 30d behelfen, aber dann wird immer 30 tageweise von heute zurück gezählt. Das wäre bei "mo" aber auch so.
Wir können unsere Datenbank-Abfrage natürlich auch sehr aufwändig vorberechnen, damit sie als Monatswerte brav die Daten vom jeweils 1. bis zum Letzten eines Monats aufsummiert.
Ich bin deshalb etwas anders vorgegangen und habe die monatlichen Werte erst im Nachgang aufsummiert. Hier das JSON dafür:
|
1 |
[{"id":"43b49e97b503b0b1","type":"influxdb in","z":"67a324f68c479a55","influxdb":"3aa60ef18acf78e3","name":"","query":"","rawOutput":false,"precision":"","retentionPolicy":"","org":"organisation","x":580,"y":560,"wires":[["79f6fde06c5cd284","bd73e12a90fff014"]]},{"id":"a6b4270f2075c6dc","type":"function","z":"67a324f68c479a55","name":"Define Query","func":"msg.query ='select time, value from verbrauch where time >(now()-365d)';\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":330,"y":560,"wires":[["43b49e97b503b0b1"]]},{"id":"743603e0ef5c093c","type":"debug","z":"67a324f68c479a55","name":"debug 24","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"payload","targetType":"msg","statusVal":"","statusType":"auto","x":1080,"y":560,"wires":[]},{"id":"8b2bf3e5276b66dc","type":"inject","z":"67a324f68c479a55","name":"","props":[{"p":"payload"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"00 03 * * *","once":true,"onceDelay":0.1,"topic":"","payload":"","payloadType":"date","x":130,"y":560,"wires":[["a6b4270f2075c6dc"]]},{"id":"79f6fde06c5cd284","type":"function","z":"67a324f68c479a55","name":"make JSON","func":"\nconst mNum = []; //Array für Monatsnummern (Label)\nconst mSum =[]; // Array fürdie monatlichen Summen\nvar series = [\"ltr\"]; // Beschriftung für Einheiit - ggf anpassen an eigene Verhältnisse \nvar mIdx = -1; // Initialwert Monatsindex\nvar lMonth = -1; // Initialwert Nummer vergangenen Monats\nvar month = -1; // Initialwert für aktuellen Monat\n\n\nfor (var i = 0; i < msg.payload.length; i++) { // Schleife über alle Werte\n var thetime = Number(msg.payload[i].time); // Auslesen der aktuellen Zeit und konvertieren in ms\n var d = new Date(thetime); // d ist das Datum des gelesenen Werts \n var month = d.getMonth() + 1; // getMonth() läuft von 0 - 11 deshalb um 1 erhöhen\n \n if (month != lMonth) { // Neuer Monat? --> initialisiere Monatswerte \n mNum.push(month); // Monat in Array schieben\n mSum.push(0); // Monatssumme nullen \n lMonth = month; // Monat und Monat des letzen Werts dind jetzt gleich \n mIdx++; // Monatsindex um 1 erhöhen \n }\n\n mSum[mIdx] = mSum[mIdx] + msg.payload[i].value; // Wert im Monat aufsummieren\n mSum[mIdx] = Math.round(mSum[mIdx]*100)/100; // Monatswert runden\n}\n//msg.payload = mSum;\nvar mNumString = '[' + mNum + ']'; // Monatsarray (enthält Label) mit Klammern umschließen\nvar mNumJSON = JSON.parse(mNumString); // JSON Objekt generieren\n\nvar mSumString = '[[' + mSum +']]'; // Wertearray (enthält Monatssummen) mit doppelten Klamern umschließen\nvar mSumJSON = JSON.parse(mSumString); //JSON Objekt generieren\n\nmsg.payload = [{\"series\":series, \"data\": mSumJSON, \"labels\": mNumJSON}]; // Übergabe an Barchart\n\nreturn msg;","outputs":1,"noerr":0,"initialize":"","finalize":"","libs":[],"x":910,"y":560,"wires":[["743603e0ef5c093c","ce2a53df3b272481"]]},{"id":"ce2a53df3b272481","type":"ui_chart","z":"67a324f68c479a55","name":"","group":"3dbf824d0f14f7e7","order":1,"width":0,"height":0,"label":"Liter GPL","chartType":"bar","legend":"false","xformat":"HH:mm:ss","interpolate":"linear","nodata":"waiting","dot":false,"ymin":"0","ymax":"","removeOlder":1,"removeOlderPoints":"","removeOlderUnit":"3600","cutout":0,"useOneColor":true,"useUTC":false,"colors":["#1f77b4","#aec7e8","#ff7f0e","#2ca02c","#98df8a","#d62728","#ff9896","#9467bd","#c5b0d5"],"outputs":1,"useDifferentColor":false,"className":"","x":1100,"y":500,"wires":[[]]},{"id":"3aa60ef18acf78e3","type":"influxdb","hostname":"127.0.0.1","port":"8086","protocol":"http","database":"apidata","name":"","usetls":false,"tls":"","influxdbVersion":"1.x","url":"http://localhost:8086","rejectUnauthorized":true},{"id":"3dbf824d0f14f7e7","type":"ui_group","name":"Monatsverbrauch letzte 365 Tage ","tab":"6e2e4833967b487c","order":3,"disp":true,"width":12,"collapse":false,"className":""},{"id":"6e2e4833967b487c","type":"ui_tab","name":"Stats","icon":"dashboard","order":5,"disabled":false,"hidden":false}] |
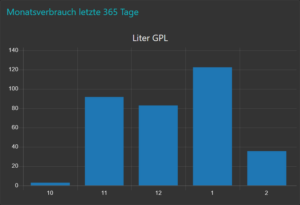
Daten für Aggregation anreichern
Wenn man vorhat, Daten über bestimmte Zeitspannen zu aggregieren, sollte man immer noch einen Datumswert wie Tag, Monat und/oder Jahr mitgeben.

Der Datensatz wird dazu wie folgt vorbereitet:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var aussen = msg.payload const d = new Date(); let month = d.getMonth() +1; //Monate laufen mit der getMonth() Methode von 0-11 let year = d.getFullYear(); msg.payload = { location: 'Nordseite', _jahr: year, _monat: month, gradc: aussen } return msg; |
Lustigerweise stellt Influx die Tabellenspalten in alphabetischer Reihenfolge dar. Damit Monat und Jahr zusammenbleiben, habe ich die Tags mit einem Unterstrich versehen, das ist natürlich Geschmackssache.
|
1 2 3 4 5 6 7 8 9 |
> select * from temperatur name: temperatur time _jahr _monat gradc location ---- ----- ------ ----- -------- 1675701285518130854 2023 2 15 Nordseite 1675701286380357650 2023 2 19 Nordseite 1675701287514756318 2023 2 6 Nordseite 1675701287702260310 2023 2 19 Nordseite > |
Aggregierte Werte direkt aus Influx
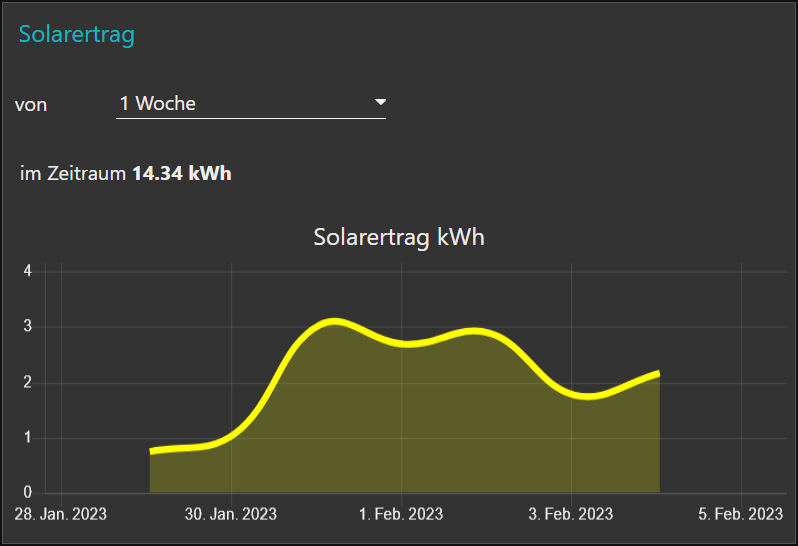
Funktioniert gerade heraus recht einfach mit den Zeitspannen, welche Influx als Zeitliterale versteht. Hat man zum Beispiel viele Messwerte über den Tag hinweg gespeichert, und möchte Tagessummen auswerten, dann geht das mit folgendem Befehl (hier für den Solarertrag):
|
1 2 |
msg.query = 'select SUM("value") from "rawYield" WHERE time > (now() - ' + msg.payload + ') GROUP BY time(1d)'; return msg; |
Heraus kommt das Solarertragsdiagramm weiter oben.
Das Aggregieren, z.B. nach dem Tag "Monat" den wir oben mit abgespeichert haben, geht natürlich genau so.
|
1 2 |
msg.query = 'select SUM("value") from "rawYield" WHERE time > (now() - ' + msg.payload + ') GROUP BY _monat'; return msg; |
Null Uhr?
Hat man ein Chart erstellt, das auf mit 1d oder ähnlich aggregierten Werten beruht, wird man feststellen, dass beim Abfahren des Graphen mit dem Cursor keineswegs 0:00 Uhr als Zeitpunkt der Messung angezeigt wird, sondern 1:00 Uhr oder bei Sommerzeit 2:00 Uhr. Das liegt daran, dass Influx intern immer mit Universal Time Coordinated [UTC] arbeitet – früher auch Greenwich Mean Time [GMT] genannt.
Bei Solarerträgen ist das unerheblich, bei anderen Messungen z.B. Stromverbräuchen etc. eher ein Problem, man möchte seine Verbräuche schließlich klar abgrenzen.
Dem hilfst du ab, indem du noch die Zeitzone an die Abfrage hinten anhängst.
Im Command Line Interface zum Beispiel so:
|
1 |
select SUM("measurement") from "bucket" WHERE time > (now() - 1d) GROUP BY time(1d) tz('Europe/Berlin') |
und in der Node Red Query fast genauso. Zusätzlich musst du die einfachen Anführungszeichen bei der Ortsangabe mit einem Backslash "escapen".
|
1 |
msg.query = 'select SUM("value") from "rawYield" WHERE time > (now() - ' + msg.payload + ') GROUP BY time(1d) tz(\'Europe/Berlin\')'; |
Bei Abfrage mit aggregierten Werten, also z.B. _day, musst du derlei Zeitzonen Klimmzüge nicht machen.
Das now() Problem – tageweise Abgrenzung
Der "Jetzt" Wert now() macht genau das, was der Name bedeutet: er zieht das Datum und die Uhrzeit von gerade eben heran, also z.B. den 20.11.2023 10:15:00
Das ist nicht immer gewünscht, vor allem dann, wenn ich eine genau tageweise Abgrenzung haben will. Mit time > (now() - 1w) liefert mir Influx, unter Zugrundelegung obigen Datums, Daten vom 13.11.2023 10:15:00 bis heute, 20.11.2023 10:15:00. Der erste Tag ist also unvollständig. Der letzte Tag auch, aber das liegt logischerweise daran, dass heute noch nicht vorbei ist 😉
Bei Influx 1.8 habe ich für das CLI noch keine Möglichkeit gefunden, das Problem mit Influx Hausmitteln zu lösen. Da wir unsere Daten ja sowieso mit Javascript vorbereiten, können wir das dort aber recht einfach lösen:
Im vorgeschalteten Query Setup Node, der die Datenbankabfrage zusammenstellt, müssen wir lediglich einen zuverlässigen Ersatz für now() erzeugen, d.h. Null Uhr des heutigen Tages als Anker, von dem aus wir die Anzahl Tage zurückgehen, über welche die Auswertung laufen soll.
|
1 2 3 |
const d = new Date(); msg.today = d.setHours(0, 0, 0, 0); // last midnight in ms msg.today = msg.today + "000000" |
In msg.today steckt jetzt der Startwert – d.h heute früh Null Uhr, erst einmal auf die MIllisekunde genau. Da Influx (blöderweise) mit Nanosekunden arbeitet, müssen wir noch eine Million dranhängen, d.h. noch 6 Nullen. Das geht problemlos als String; Javascript bzw NR ist in Bezug auf gemischte Zahl- und Stringwerte sehr tolerant.
Der Query String wird jetzt aufgrund der in den String einzufügenden msg.today und msg.payload etwas aufwendiger:
|
1 |
msg.query = 'select SUM(sum) from hourpvprod WHERE time > (' + msg.today + ' - ' + msg.payload +') GROUP BY time(1d) tz(\'Europe/Berlin\')'; |
(hourpvprod ist eine Tabelle mit aggregierten Stundenwerten, der Solaranlage)
Mit dieser Abfrage habt ihr eine tagesgenaue Auswertung zur Hand.
Dieser Beitrag wurde inspiriert von https://funprojects.blog/2020/02/01/influxdb-with-node-red/